
Abstract
In the artificial intelligence landscape, a quiet revolution is underway. Mistral AI, Europe's rising AI star, has just made a major impact with Mistral Medium 3, a model that disrupts established conventions. In a market dominated by the race for parameters and raw performance, Mistral proposes a radically different approach: delivering exceptional capabilities including 91% accuracy on mathematical reasoning, 97.1% on instruction following, and comprehensive multimodal support - all at a fraction of the cost of comparable models.
This technical achievement is more than simple optimization. It's a fundamental rethinking of how we design and deploy AI. With usage costs 8 times lower than comparable models and the ability to run on just 4 GPUs, Mistral Medium 3 democratizes access to cutting-edge AI for organizations of all sizes. More than a model, it's a new philosophy: why pay for excess capabilities when efficiency can deliver exceptional results?
The impact is already tangible. From startups to multinationals, companies are rethinking their AI strategies. The promise is simple yet powerful: world-class artificial intelligence, adaptable to your specific needs, without compromising your budget or infrastructure. Mistral Medium 3 isn't just an economical alternative - it's proof that innovation can go hand in hand with accessibility.
Architecture and Technical Innovations
At the heart of Mistral Medium 3 lies a next-generation Mixture-of-Experts (MoE) architecture, the result of years of research and optimization. Unlike traditional dense architectures where all parameters are activated for each query, Mistral's MoE approach selectively activates specialized expert subsets, maximizing computational efficiency while maintaining exceptional performance.
Mistral's proprietary architecture, while kept secret in its finest details, relies on improved routing algorithms that intelligently direct queries to the most relevant experts. This approach allows the model to achieve performance comparable to much larger models - estimated around 33 billion parameters - while requiring significantly fewer computational resources during inference.
The 131,072 token context capacity represents another major asset. This extended context window allows processing entire documents, complex codebases, or prolonged conversations without information loss. Native support for 12 languages - including English, French, German, Spanish, Italian, Portuguese, Dutch, Polish, Ukrainian, Czech, Romanian, and Swedish - makes it a truly international solution, particularly relevant for multilingual organizations.
Benchmarks: Performance That Defies Convention
Mistral Medium 3's benchmark results tell a remarkable story. In a world where size has long been synonymous with performance, this model proves that architectural efficiency can surpass brute force. The numbers speak for themselves and deserve thorough analysis.
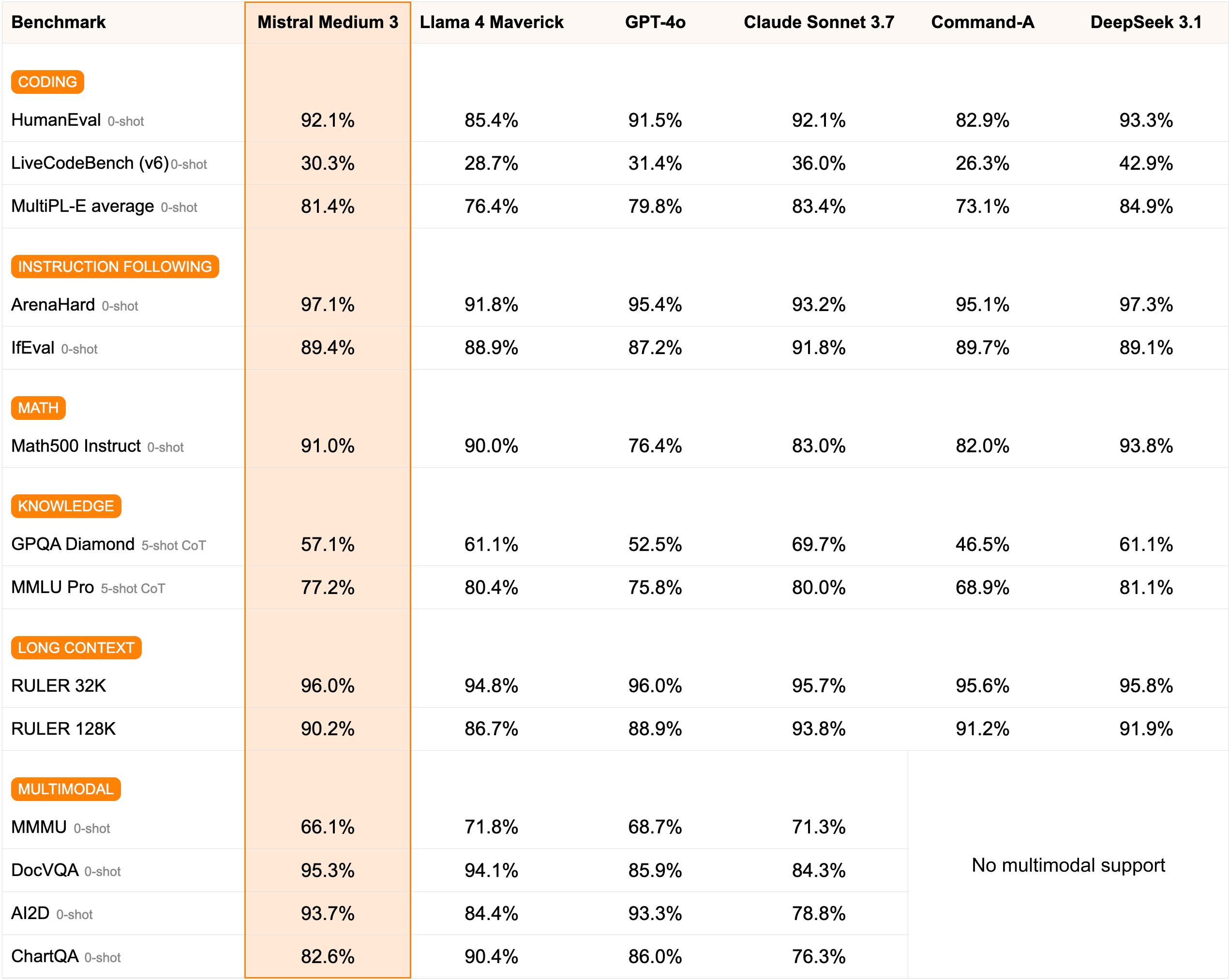
Mistral Medium 3 excels across multiple benchmarks, showcasing its versatility and power. In coding tasks, the model achieves an impressive 92.1% on HumanEval (matching Claude Sonnet 3.7), 30.3% on the challenging LiveCodeBench, and 81.4% average on MultiPL-E. These scores position Mistral Medium 3 as a formidable coding assistant, competitive with models costing significantly more.
The model truly shines in mathematical reasoning, achieving 91.0% on Math500 Instruct - outperforming GPT-4o (76.4%) and Claude Sonnet 3.7 (83.0%) by substantial margins. In instruction following, Mistral Medium 3 demonstrates exceptional capability with 97.1% on ArenaHard and 89.4% on IfEval, proving its reliability for applications requiring precise task execution.
For knowledge benchmarks, the model achieves 57.1% on GPQA Diamond and 77.2% on MMLU Pro, showing solid performance while leaving room for improvement compared to some competitors. However, its long-context capabilities are outstanding, with 96.0% on RULER 32K and 90.2% on RULER 128K, making it ideal for processing extensive documents and maintaining coherence across long conversations.
.png)
Human evaluations provide compelling evidence of Mistral Medium 3's competitive edge. When pitted against Llama 4 Maverick, Mistral Medium 3 demonstrates clear superiority across multiple domains: achieving an 81.82% win rate in coding tasks, 71.43% in French language tasks, 73.33% in Spanish, and maintaining strong performance in English (66.67%), German (62.50%), and Arabic (64.71%). Even in multimodal tasks, where one might expect larger models to dominate, Mistral Medium 3 holds its own with a 53.85% win rate.
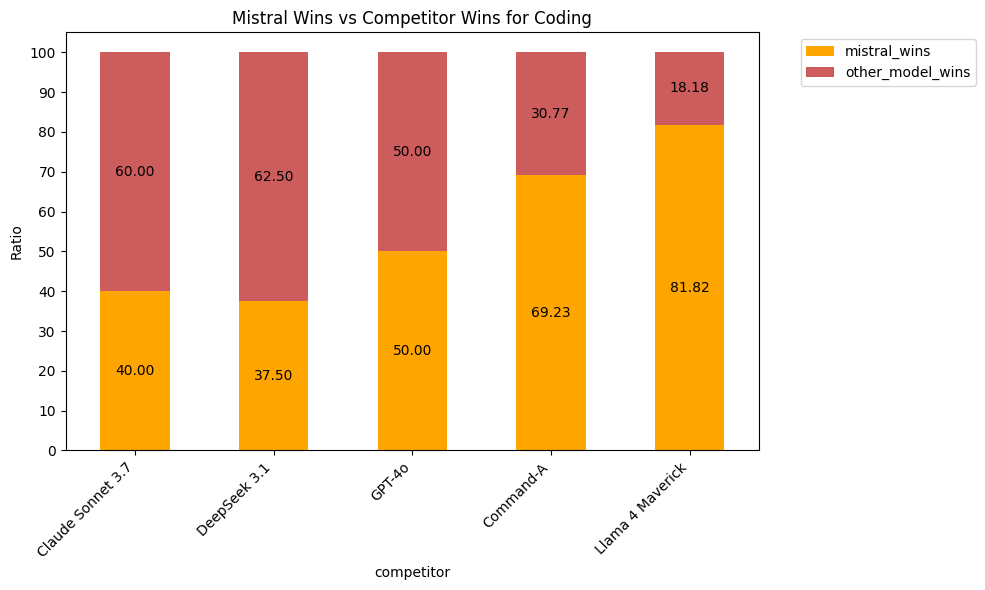
Coding performance analysis reveals a nuanced competitive landscape. In head-to-head coding comparisons, Mistral Medium 3 achieves a 50% win rate against GPT-4o (indicating parity), wins 69.23% of the time against Command-A, and maintains strong performance with 40% wins against Claude Sonnet 3.7 and 37.5% against DeepSeek 3.1. While it faces tougher competition from the top-tier models, its dominant 81.82% win rate against Llama 4 Maverick and competitive showing against others demonstrate that Mistral Medium 3 delivers professional-grade coding capabilities at a fraction of the cost.
Remarkably, Mistral Medium 3 also supports multimodal capabilities, achieving strong scores across visual understanding tasks: 66.1% on MMMU, an exceptional 95.3% on DocVQA, 93.7% on AI2D, and 82.6% on ChartQA. This positions it as one of the few models in its price range offering comprehensive multimodal support, contrary to many competitors like DeepSeek 3.1 which lack these capabilities entirely.
Deployment and Implementation: Simplicity in Service of Efficiency
One of Mistral Medium 3's major assets lies in its deployment ease. Unlike massive models requiring complex infrastructure, Mistral Medium 3 can run on a modest 4-GPU configuration, making cutting-edge AI accessible to a much broader range of organizations.
Deployment via the Mistral API represents the simplest solution for getting started quickly:
from mistralai import Mistral
import os
# Initialize Mistral client
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
# Example usage for reasoning task
def analyze_business_problem(context, question):
response = client.chat.complete(
model="mistral-medium-latest",
messages=[
{
"role": "system",
"content": "You are an expert business analyst. Provide detailed and structured analyses."
},
{
"role": "user",
"content": f"Context: {context}\n\nQuestion: {question}"
}
],
temperature=0.7,
max_tokens=2000
)
return response.choices[0].message.content
# Usage for data analysis
def process_financial_data(data_description, analysis_type):
prompt = f"""
Analyze the following financial data:
{data_description}
Analysis type requested: {analysis_type}
Provide:
1. Summary of key points
2. Actionable insights
3. Strategic recommendations
"""
response = client.chat.complete(
model="mistral-medium-latest",
messages=[{"role": "user", "content": prompt}],
temperature=0.3 # Lower for precise analyses
)
return response.choices[0].message.contentFor on-premise deployments or those requiring more control, using vLLM offers optimized performance:
# Install dependencies for local deployment
pip install vllm>=0.6.3
pip install transformers>=4.40.0
pip install torch>=2.0.0
# Launch vLLM server (requires model access)
python -m vllm.entrypoints.openai.api_server \
--model mistralai/mistral-medium-latest \
--dtype half \
--tensor-parallel-size 4 \
--max-model-len 131072Integration with major cloud platforms further simplifies deployment:
# Deployment on Amazon SageMaker
import boto3
from sagemaker.huggingface import HuggingFaceModel
# Model configuration
hub = {
'HF_MODEL_ID': 'mistralai/mistral-medium-latest',
'HF_TASK': 'text-generation',
'HF_API_TOKEN': os.environ["HF_API_TOKEN"]
}
# Create and deploy endpoint
huggingface_model = HuggingFaceModel(
transformers_version='4.37.0',
pytorch_version='2.1.0',
py_version='py310',
model_data=model_data_url,
role=role,
env=hub
)
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type='ml.g5.12xlarge',
endpoint_name='mistral-medium-endpoint'
)Real-World Applications: Beyond Benchmarks
Mistral Medium 3's true value reveals itself in concrete real-world applications. Its unique ability to adapt to organizations' specific contexts opens transformative possibilities across numerous sectors.
In the financial sector, the model excels at real-time risk analysis, capable of processing massive volumes of transactional data while identifying complex fraud patterns. Banking institutions are already using Mistral Medium 3 to automate compliance report generation, reducing processing times from days to hours while improving accuracy and consistency.
The healthcare sector particularly benefits from the model's multilingual capabilities. European hospitals use it to analyze medical records in different languages, facilitating cross-border collaboration and improving care continuity. The model's ability to process long medical documents through its extended context window enables holistic analysis of patient histories.
The manufacturing industry leverages Mistral Medium 3 for production chain optimization. By analyzing IoT sensor data, maintenance logs, and quality reports, the model proactively identifies failure risks and suggests process optimizations. This predictive approach has enabled some companies to reduce unplanned downtime by over 40%.
Cost-Performance Analysis: The Economic Revolution
Mistral Medium 3's economic equation redefines industry standards. With rates of $0.4 per million input tokens and $2 for output, the model offers unprecedented value in its performance category.
Consider the concrete example of a company processing 100 million tokens per day (equivalent to about 75,000 pages of text). With GPT-4, this volume would represent a daily cost of approximately $3,000. With Mistral Medium 3, the same volume costs only $240 - over 90% savings for comparable performance in many use cases.
This cost difference becomes even more significant when considering on-premise deployments. The ability to run on just 4 GPUs represents substantial infrastructure savings. A 4 NVIDIA A100 configuration costs around $80,000, versus over $500,000 for the infrastructure required by comparable models. Energy savings follow a similar curve, with 75% reduced consumption for equivalent workloads.
The impact on ROI is transformative. Companies report payback periods under 6 months, versus 2-3 years for larger model deployments. This speed enables more aggressive experimentation and broader AI adoption within organizations.
Limitations and Strategic Considerations
Despite its many strengths, Mistral Medium 3 presents certain limitations that are crucial to understand for successful deployment. While the model includes multimodal capabilities with strong performance on visual tasks, it may not match the most advanced multimodal models in complex image generation or video understanding tasks.
In knowledge-intensive benchmarks like GPQA Diamond (57.1%), Mistral Medium 3 shows room for improvement compared to leaders like Claude Sonnet 3.7 (69.7%). This suggests that for highly specialized scientific or technical knowledge queries, supplementary resources may be beneficial.
Complex spatial reasoning tasks and certain edge cases in mathematical proofs can occasionally challenge the model. While it excels at practical mathematical problem-solving (91% on Math500), theoretical mathematics at the research level may require more specialized tools.
It's also important to note that, unlike some fully transparent open-source models, Mistral Medium 3's exact architecture remains proprietary. While this doesn't affect performance or usage, organizations with strict algorithmic transparency requirements must take this into account.
The Future of AI
Mistral Medium 3 represents more than just technological evolution - it's a paradigm shift in how we conceive AI deployment. By demonstrating that it's possible to achieve cutting-edge performance with a fraction of traditionally required resources, Mistral paves the way for unprecedented democratization of advanced AI.
The ecosystem impact is already visible. Cloud providers are adapting their offerings to optimize efficient model deployment. Companies are rethinking their AI strategies, moving from a "one model for everything" approach to modular architectures using specialized models. This evolution fosters innovation and experimentation, reducing entry barriers for SMEs and startups.
Mistral's roadmap suggests even more promising developments. With already strong multimodal capabilities in place, future iterations will likely enhance these features while maintaining the efficiency that is the brand's signature. The model's excellence in instruction following (97.1% on ArenaHard), mathematical reasoning (91% on Math500), and long-context handling (96% on RULER 32K) positions it as an ideal foundation for AI systems. Native integration with various systems and continuous improvement of fine-tuning capabilities position Mistral Medium as an evolving AI platform rather than just a model.
Conclusion: Efficiency as the New Frontier
Mistral Medium 3 embodies a fundamental truth often overlooked in the race to AGI: the most useful artificial intelligence isn't necessarily the largest or most expensive. By offering 90% of capabilities for 12.5% of the cost, Mistral redefines the AI value proposition.
For technology decision-makers, the message is clear: the era of accessible and efficient AI has arrived. Traditional barriers - cost, complexity, infrastructure - collapse in the face of solutions like Mistral Medium 3. The question is no longer whether your organization can afford to adopt advanced AI, but rather whether it can afford not to.
The future belongs to organizations that know how to intelligently leverage these new capabilities. Mistral Medium 3 isn't just a tool - it's a catalyst for digital transformation, offering cutting-edge AI power in an accessible, efficient package adapted to modern organizational realities.
Essential Resources:
Ready to transform your AI infrastructure with Mistral Medium 3? Contact Arcenal for a personalized consultation and discover how to optimize your AI deployments while significantly reducing operational costs.
