
Abstract
We are releasing Arcenal-Small-8b, an 8B parameter reasoning model built on the Qwen3 architecture. Starting from DeepSeek-R1-0528-Qwen3-8B (a distilled version of DeepSeek-R1), we fine-tuned the model using LoRA and GRPO techniques. We also integrated the OpenChina dataset to remove censorship constraints, resulting in a reasoning model that delivers strong performance without artificial limitations.
Benchmark Performance
The base DeepSeek-R1-0528-Qwen3-8B model already exhibited exceptional reasoning capabilities. Our challenge was to remove its censorship constraints while preserving these strengths. Not only did we successfully uncensor the model through our fine-tuning process, but we also managed to maintain and even improve its performance on key benchmarks.
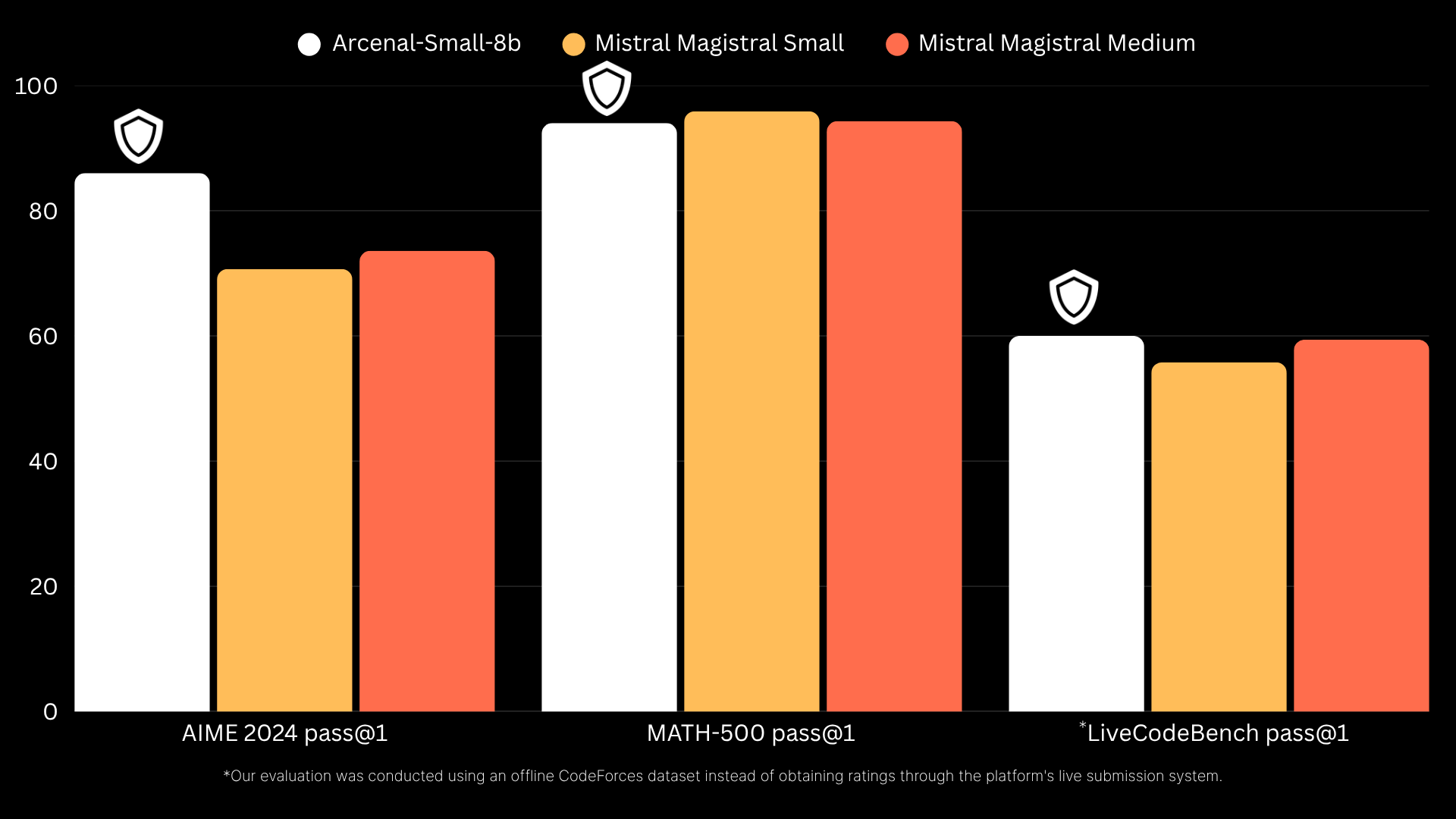
Arcenal-Small-8b demonstrates superior performance across critical reasoning benchmarks, outperforming both Mistral Magistral Small and Medium models in key areas:
| Model | AIME 2024 pass@1 | MATH-500 pass@1 | LiveCodeBench pass@1 |
|---|---|---|---|
| Arcenal-Small-8b | 86% | 94% | 60% |
| Mistral Magistral Small | 71% | 96% | 56% |
| Mistral Magistral Medium | 74% | 94% | 59% |
The model achieves particularly impressive results on the AIME 2024 benchmark with 86% pass@1, significantly outperforming both Mistral variants. While maintaining competitive performance on MATH-500 (94%), it also edges ahead on LiveCodeBench with 60% pass@1, demonstrating well-rounded capabilities across mathematical reasoning and code generation tasks.
Architecture and Training
Arcenal-Small-8b builds upon the strong foundation of DeepSeek-R1-0528-Qwen3-8B, a distilled version of the groundbreaking DeepSeek-R1-0528 model. The base model already demonstrated exceptional performance across reasoning benchmarks, but suffered from a critical limitation: systematic censorship aligned with Chinese government policies. Our approach addressed this while preserving its strengths:
- Base Model: DeepSeek-R1-0528-Qwen3-8B distillation
- Fine-tuning: LoRA (Low-Rank Adaptation) for efficient parameter updates
- Optimization: GRPO (Gradient Reward Policy Optimization) for enhanced reasoning
- Uncensoring: OpenChina dataset integration to remove artificial constraints
This combination preserves the exceptional reasoning capabilities of the original model while ensuring unbiased, uncensored responses across all domains.
Conclusion
Arcenal-Small-8b represents a new standard in efficient reasoning models, combining state-of-the-art performance with complete freedom from censorship. At just 8 billion parameters, it offers an optimal balance between capability and computational efficiency, making it suitable for both research and production deployments.
The model is now available for immediate use, empowering developers and researchers with unconstrained AI reasoning capabilities. You can try Arcenal-Small-8b right now at chat.arcenal.org by enabling reasoning mode. Our chat interface is completely free and offers a seamless way to experience the model's uncensored reasoning capabilities firsthand.
We plan to open-source Arcenal-Small-8b soon, making it freely available to the community for further research and development.
Interested in deploying uncensored AI models or building on our technology? Reach out to discuss how Arcenal can accelerate your AI initiatives.
