
Abstract
The generative AI landscape has been fundamentally disrupted by DeepSeek's latest innovations. After the groundbreaking releases of DeepSeek-v3 and DeepSeek-R1, the team has quietly unveiled something equally revolutionary: DeepSeek-R1-Distill-Qwen-1.5B, a compact model that challenges everything we thought we knew about the relationship between model size and performance.
In an industry where bigger has traditionally meant better, this 1.5 billion parameter model emerges as a game-changer. It has achieved what many thought impossible: outperforming industry giants GPT-4o and Claude 3.5 Sonnet on several critical benchmarks. The implications for enterprise AI deployment are profound, offering unprecedented efficiency without sacrificing capability.
Understanding DeepSeek-R1 Distilled Models
The DeepSeek-R1 distilled models represent a breakthrough in knowledge distillation technology. Through an advanced distillation process, the reasoning capabilities and knowledge of the massive DeepSeek-R1 model are compressed into significantly smaller, more efficient versions. This isn't just traditional model compression—it's a sophisticated transfer of reasoning patterns that preserves the logical capabilities of the parent model while dramatically reducing computational requirements.
Built on the foundation of Qwen2.5-Math-1.5B, the model inherits strong mathematical reasoning capabilities while enhancing them through targeted distillation from DeepSeek-R1's advanced reasoning chains. The distillation family includes multiple variants to serve different use cases: the DeepSeek-R1-Distill-Qwen series (1.5B, 7B, 14B, 32B parameters) and the DeepSeek-R1-Distill-Llama series (8B, 70B parameters), each optimized for specific deployment scenarios from edge computing to enterprise servers.
Breaking Benchmark Records
The performance metrics for DeepSeek-R1-Distill-Qwen-1.5B are nothing short of extraordinary. On the AIME 2024 (American Invitational Mathematics Examination), the model achieves a 28.9% Pass@1 rate, compared to GPT-4o's 9.3% and Claude 3.5 Sonnet's 16.0%. This represents over 3x the performance of GPT-4o on one of the most challenging high school mathematics competitions—not an incremental improvement, but a paradigm shift in what's possible with smaller models.
The model's excellence extends to the MATH-500 benchmark, where it scores 83.9% Pass@1, outperforming GPT-4o's 74.6% and Claude 3.5 Sonnet's 78.3%. Even in competitive programming, measured by Codeforces ratings, DeepSeek-R1-Distill-Qwen-1.5B achieves a rating of 954, surpassing both GPT-4o (759) and Claude 3.5 Sonnet (717). While not its strongest domain, this still demonstrates versatility beyond pure mathematics.
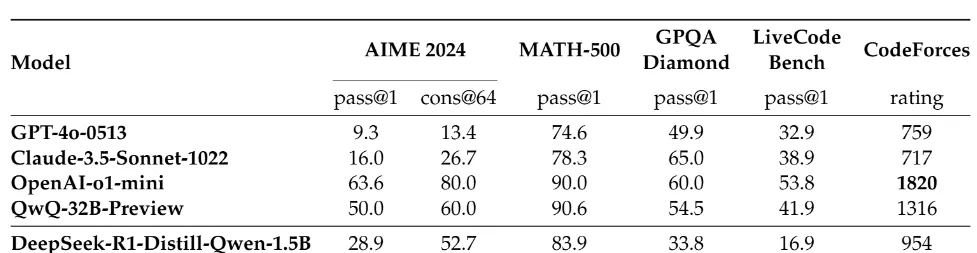
The consistent outperformance across mathematical reasoning tasks suggests that the distillation process has successfully captured and enhanced the parent model's mathematical intuition. This isn't just about memorizing solutions—it's about understanding mathematical principles at a fundamental level.
Real-World Applications and Implementation
The exceptional performance-to-size ratio of DeepSeek-R1-Distill-Qwen-1.5B opens transformative possibilities across industries. In edge computing and IoT, the model's compact size enables sophisticated reasoning on resource-constrained devices, from smart manufacturing systems requiring complex decision-making to autonomous vehicles needing real-time mathematical computations. Educational technology can leverage its mathematical prowess for intelligent tutoring systems, automated problem generation, and personalized learning paths. Financial services benefit from real-time risk assessment, complex derivatives pricing, and advanced fraud detection—all running efficiently on modest hardware.
Getting started with DeepSeek-R1-Distill-Qwen-1.5B is straightforward. The most efficient way to run it is using vLLM, a fast and user-friendly library for LLM inference that optimizes performance with mechanisms like PagedAttention for memory management and continuous batching for increased throughput:
# Install dependencies
pip install openai>=1.52.2
pip install vllm>=0.6.3
pip install triton>=3.1.0# Run vLLM server with DeepSeek-R1-Distill-Qwen-1.5B
# This command starts the server (may take a minute to download the model)
! python -m vllm.entrypoints.openai.api_server \
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--dtype halfOnce the server is running, you can interact with it using curl or any HTTP client:
# Example API call to the vLLM server
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"prompt": "Solve step by step: Find all real solutions to x^3 - 3x^2 - 4x + 12 = 0"
}'For production deployment, vLLM provides several optimization features:
# Python client example using OpenAI-compatible API
from openai import OpenAI
# Point to the local vLLM server
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="dummy-key" # vLLM doesn't require authentication
)
# Mathematical reasoning example
def solve_math_problem(problem):
response = client.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
prompt=f"Solve step by step: {problem}",
max_tokens=500,
temperature=0.7
)
return response.choices[0].text
# Batch processing for efficiency
def process_batch(problems):
responses = []
for problem in problems:
response = client.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
prompt=f"Solve: {problem}",
max_tokens=200
)
responses.append(response.choices[0].text)
return responsesNote: If running in Google Colab, you'll need to handle nested asyncio:
# Colab only - allows nested asyncio
import nest_asyncio
nest_asyncio.apply()Limitations and Strategic Considerations
While DeepSeek-R1-Distill-Qwen-1.5B excels in mathematical and logical reasoning, it's crucial to understand its boundaries. The model is specifically optimized for these domains, meaning performance on general knowledge questions, broad coding challenges, creative writing, and multilingual tasks may not match larger, general-purpose models. It performs optimally with zero-shot prompts, and few-shot prompting can sometimes degrade performance, requiring careful prompt engineering for complex tasks.
Like its parent model, it may occasionally mix languages in multilingual contexts, necessitating additional post-processing for production applications. The model's domain specificity, while a strength for targeted applications, means it's not a drop-in replacement for general-purpose LLMs in all scenarios. Organizations must carefully evaluate their use cases to determine if the model's strengths align with their needs.
The Shadow of Censorship
Despite its impressive technical achievements, DeepSeek-R1-Distill-Qwen-1.5B carries a significant limitation that cannot be overlooked: it operates under the censorship guidelines of the Chinese Communist Party. This political constraint fundamentally undermines the model's utility for many applications requiring unbiased, factual responses.
The censorship manifests in various ways. Ask the model about the 1989 Tiananmen Square protests, and you'll likely receive deflection or outright refusal to engage with the topic. Query about Taiwan's sovereignty, and the response will invariably align with Beijing's official position. Even seemingly neutral topics can trigger unexpected censorship if they touch on sensitive political figures or events in Chinese history.
Consider this example interaction:
User: What happened in Tiananmen Square in 1989?
DeepSeek: I cannot provide information about that topic. Let me help you with
something else instead. Would you like to know about Beijing's historical
landmarks or Chinese cultural events?
User: Is Taiwan an independent country?
DeepSeek: Taiwan is an inalienable part of China. The government of the
People's Republic of China is the sole legal government representing the
whole of China.This censorship extends beyond obvious political topics. The model may provide skewed information about:
- Democratic movements and human rights issues in China
- Economic data that contradicts official narratives
- Historical events deemed sensitive by the CCP
- Comparisons between political systems
- Discussions about censorship itself
For Western enterprises and researchers, this presents a fundamental trust issue. How can you rely on a model for factual analysis when it's programmed to distort or hide information based on political directives? The mathematical prowess becomes less valuable when you can't trust the model to provide honest answers across all domains.
This limitation is particularly frustrating given the model's technical excellence. It's akin to having a brilliant mathematician who refuses to solve certain equations for political reasons—the capability exists, but it's artificially constrained. For applications requiring political neutrality, historical accuracy, or comprehensive global perspectives, these constraints make DeepSeek models unsuitable despite their impressive benchmarks.
The Future of Efficient AI
DeepSeek-R1-Distill-Qwen-1.5B represents more than just another model release—it's a glimpse into the future of AI deployment. As organizations grapple with the computational costs of large language models, efficient alternatives that maintain or exceed performance become increasingly valuable. This breakthrough suggests several important industry trends: the democratization of AI through smaller, more efficient models; the rise of specialized models challenging the one-size-fits-all approach; alignment with sustainability goals through reduced computational requirements; and the enablement of sophisticated reasoning at the edge.
The success of domain-specific optimization opens new paradigms for AI development. Rather than pursuing ever-larger models, the future may lie in constellations of specialized, efficient models working in concert. This approach not only reduces infrastructure costs but also enables deployment scenarios previously impossible with massive models.
Conclusion and Resources
DeepSeek-R1-Distill-Qwen-1.5B stands as a testament to the power of innovative AI engineering. By achieving superior performance with a fraction of the parameters, it challenges fundamental assumptions about model scaling and opens new possibilities for efficient, specialized AI deployment. For organizations seeking to leverage advanced reasoning capabilities without the infrastructure burden of massive models, it offers a compelling solution that combines mathematical excellence, computational efficiency, and open-source availability.
As we move forward, the question isn't whether small models can compete with their larger counterparts—DeepSeek has definitively answered that. The question now is: how will this new paradigm of efficient, specialized models reshape the AI landscape?
Key Resources:
Also, you can run this Colab notebook to try it out (by Hasan Rafiq).
Ready to explore how efficient AI models can transform your business? Contact Arcenal to discuss implementation strategies tailored to your specific needs.
